Histoire de la traduction automatique
La traduction automatique est un sous-champ de linguistique computationnelle qui étudie l'utilisation de logiciels pour traduire le texte ou la parole d'une langue naturelle à une autre.
L'histoire de la traduction automatique questionne le besoin pour l'automatisation de la traduction d'avoir recours à la traduction automatique[1].
Elle appartient à l'industrie langagière.
Histoire
Premier projet
En 1931, pour répondre à un besoin public, l'ingénieur soviétique Smirnov-Troianski envisage le premier projet de machine à traduire[1], d'après les russes.
Premières recherches

En 1943 et 1953, l'UNESCO se rend compte de l'augmentation des besoins mondiaux en traductions scientifiques et techniques, du manque de formation des traducteurs et du coût élevé des traductions[1].
En 1948, la faisabilité de traductions à l'aide d'une calculatrice électronique est envisagée en Grande-Bretagne et aux Etats-Unis[1].
En 1949, Warren Weaver publie un memorandum sur la traduction automatique des langues naturelles[2] qui est à la fois visionnaire et optimiste sur l'avenir de l'intelligence artificielle.
En 1954, la faisabilité de traductions à l'aide d'une calculatrice électronique est envisagée en Union Soviétique[1].
Origines

En 1954 commence la première expérience publique de traduction automatique par des chercheurs d’IBM et de l’université Georgetown de Washington DC, qui espéraient atteindre la traduction automatique instantanée de qualité du russe vers l’anglais en quelques années[3].
En janvier 1954, à New York, une première démonstration sur IBM 701 permet la traduction depuis le russe vers l'anglais de phrases pouvant utiliser jusqu'à 250 mots et six règles de syntaxe. La mise en valeur par la presse fr cette démonstration impressionne une partie du public et quelques scientifiques[1].
Dans les années 1950, la traduction automatique est devenue une réalité dans la recherche, bien que des références au sujet peuvent être trouvées dès le XVIIe siècle. L'expérience de Georgetown, qui impliquait une traduction entièrement automatique réussie de plus de soixante phrases russes en anglais en 1954, fut l'un des premiers projets enregistrés. Les chercheurs de l'expérience de Georgetown ont affirmé leur conviction que la traduction automatique serait un problème résolu dans les trois à cinq ans. En Union soviétique, des expériences similaires ont été effectuées peu de temps après. Par conséquent, le succès de l'expérience a donné le début d'une ère de financement important pour la recherche sur la traduction automatique aux États-Unis.
En 1956, le 20e congrès du PCUS approuve la recherche en traduction automatique[1].
En 1958, Moscou organiser le premier congrès de traduction automatique, regroupant 340 participants de 79 institutions[1].
La recherche se développe ensuite à un niveau international: en 1956 le Japon, en 1957 la Tchécoslovaquie, en 1958-59 la Chine, en 1959 l'Italie et la France, en 1960 le Mexique, en 1961 la Belgique . Toutefois, certains pays comme la République fédérale d'Allemagne, la Suède et la Finlande ne développent pas ces recherches[1].
La France ne peut s'intéresser plus tôt à la traduction automatique du fait du caractère analogique des calculateurs analogiques et par manque de calculateur numérique (affaire Couffignal)[1].
En février et mars 1958, en France, É. Delavenay organise deux réunions sur la « machine à traduire ». Des personnes comme Georges-Théodule Guilbaud, Benoît Mandelbrot ou Marcel-Paul Schützenberger ou Clemens Heller y assistent. À cette époque, le sujet n'intéresse pas les linguistes français[1].
En septembre 1959 est créé l'Association pour l'étude et le développement de la traduction automatique et de la linguistique appliquée (ATALA)[1].
Les premières traductions automatiques (du moins à partir de 1962[4]) étaient connues pour être des traductions littérales — également dites mot-à-mot, ou word for word en anglais — car elles utilisaient simplement une base de données de mots et leurs traductions.
Les progrès réalisés ont été beaucoup plus lents que prévu; en 1966, le rapport de l'ALPAC a révélé que dix années de recherche n'avaient pas répondu aux attentes de l'expérience de Georgetown et ont entraîné une réduction spectaculaire du financement.
En 1966 et après le rapport de l'ALPAC (Automatic Language Processing Advisory Committee) les Français ont presque été le seul pays de la planète à continuer les recherches relatives à la traduction[1]
La traduction automatique ne peut plus être financée que par l'intelligence artificielle, dans les années 1970[1].
Années 1970
Dans les années 1970, le logiciel Systran développe ses activités mainframe au Canada et en Europe.
En 1968 et en 1970 respectivement, aux États-Unis, sont fondées les sociétés SYSTRAN (Peter Toma) et Logos (Bernard Scott) pour servir le DoD (Department of Defense) des États-Unis.
En 1970, le système SYSTRAN est installé pour la United States Air Force.
En 1976, le système SYSTRAN est installé pour le précurseur lde la Commission européenne qu'est la Commission des Communautés européennes.
En 1968, en Europe, est initiée la version initiale du système de traduction automatique Systran (SYStem TRANslation), «Systran Mainframe», commercialisé par World Translation Center Inc. et sociétés affiliées[5].
En 1975, un contrat avec WTC permet d'utiliser le système pour ses services de traduction, dans la version «EC-Systran Mainframe»[5].
Des contrats signés entre 1976 et 1987 avec WTC cherchent à passer à neuf couples de langues[5].
En 1977, le Canada installe le METEO System, developpé à l'Université de Montréal, pour traduire les prévisions météorologiques depuis l'anglais vers le français, pour traduire près de 80 000 mots par jour soit 30 million de mots par année jusqu'au remplacement par un ststème concurrent le 30 Septembre 2001[6].
Décennies 1980 et 1990
Systran 1980-1999
A partir de septembre 1985, un ensemble de contrats permettent à Gachot SA d'acquérir les sociétés du groupe WTC, propriétaires de la technologie Systran et de la version Systran Mainframe du système de traduction automatique Systran. Ce groupe d'entreprise s'est dénommé groupe Systran[5].
Le 4 août 1987, le groupe Systran et la Commission signent un contrat pour organiser ensemble le développement et l’amélioration du système de traduction automatique Systran[5].
En 1988 et 1989, la Commission obtient de Gachot une «licence d’utilisation» du système de traduction automatique Systran pour les couples de langues allemand-anglais, allemand-français, anglais-grec, espagnol-anglais et espagnol-français[5].
En décembre 1991, la Commission dénonce le contrat considérant que Systran ne respecte pas ses obligations contractuelles. La version EC-Systran Mainframe compte alors seize versions linguistiques[5].
Par la suite, Systran crée «Systran Unix» pouvant fonctionner sous Unix et Windows[5].
La Commission a développé la version EC-Systran Mainframe[5].
A partir de décembre 1997, des contrats de migration sont mis en place pour permettre au versions mainframe de l'union européenne de fonctionner sous Unix et sous Windows. Ce système est nommé «EC-Systran Unix»[5].
La société Systran donne à la Commission la marque Systran de manière systématique pour tout système de traduction automatique dérivant du système de traduction automatique Systran d’origine aux seules fins de la diffusion ou de la mise à disposition de ce système[5].
Traduction de langues distribuée 1980-1999
De 1981 à 1990, le projet traduction de langues distribuée a été développé et a coûté 6,5 millions d'euros financés à 46 % par le Ministère néerlandais des Affaires économiques, 52 % par BSO. La Commission européenne avait investi les deux premiers pourcents.
Autres logiciels 1980-1999


L'intérêt s'est accru pour les modèles statistiques pour la traduction automatique, qui sont devenus plus fréquents et aussi moins coûteux dans les années 1980 à mesure que la puissance de calcul disponible augmentait.
Dans la décennie 1980, à la fois le diversité et le nombre des systèmes installés pour la traduction automatisée a augmenté. Certains systèmes utilisaient la technologie mainframe, comme SYSTRAN, Logos, Ariane-G5, et Metal.[réf. nécessaire]
A la fin de la décennie 1980, une émergence large de nouvelles méthodes de traduction automatique apparaît. Un système est développé par IBM basé sur des méthodes statistical methods. Makoto Nagao et son groupe utilisent des méthodes basées sur un grand nombre d'exemples de traductions, une technique maintenant nommée example-based machine translation[7],[8]. Une qualité définissant chacune de ces deux approches était l'omission de règles syntaxiques et sémantique et la dépendances dans le manipulation de corpus de textes étendus.
Durant la décennie 1990, encouragé par les succès de la speech recognition et de la speech synthesis, la recherche dans la traduction de la parole commença avec le développement du projet allemand Verbmobil.
Le système Forward Area Language Converter (FALCon), une technologie de traduction automatique conçue par l' Army Research Laboratory, a été en 1997 pour traduire des documents de soldats en Bosnie-Herzégovine[9].
Une croissance significative de l'utilisation de la traduction automatique s'est produite sous l'effet des avancées et des moindres coûts d'ordinateur dont la puissance augmente. Au début des années 1990, la traduction automatique commence à s'affranchir des grands mainframe computers pour fonctionner des des ordinateurs personnels et sur des workstations. Deux sociétés qui mènent le marché des PC un temps sont Globalink et MicroTac, qui fusionnent (en Décembre 1994). Intergraph et Systran commencent à offrir des versions PC à cette époque. Des sites web deviennent disponibles sur Internet, comme le Babel Fish d'AltaVista (qui utilise la technologie Systran) et le Google Language Tools (initialement basé sur la technologie Systran).
Suite à la disponibilité améliorée des microordinateurs, un marché émerge pour des terminaux de traduction automatisée.
Décennie 2000
Le champ de la traduction automatique a connu des changements majeurs dans les années 2000s. Une grande quantité de recherche a été faite sur le statistical machine translation et l' example-based machine translation.
Dans le domaine de la traduction ou du doublage de la parole, la recherche s'est focalisée sur le passage de systèmes limités par le domaine à des systèmes de traducitons non limités par le domaine. Dans différents projets de recherche européens (comme TC-STAR)[10] et aux Éetats-Unis (STR-DUST et DARPA Global autonomous language exploitation program), des solutions pour traduire automatiquement des discours parlementaires et diffuser les nouvelles ont été développées. Dans ces scenari le domaine du contenu n'est plus limité au aucun domaine spécifique, mais les discours à traduire couvrent plutôt des sujets variés.
Le projet franco-allemand Quaero a envisagé la possibilité d'utilisaer la traduciton automatique pour un Internet multilingue. Le projet visait à ne pas seulement traduire des pages web, mais aussi de traduire des vidéos et des fichiers audio sur l'Internet.
Bien qu'il n'existe pas de système autonome de « traduction de haute qualité entièrement automatique de texte sans restriction », il existe maintenant de nombreux programmes disponibles qui sont capables de fournir une production utile dans des contraintes strictes. Plusieurs de ces programmes sont disponibles en ligne, tels que Google Translate et le système SYSTRAN qui alimente BabelFish d'AltaVista (maintenant Babelfish de Yahoo à partir du ).
En 2009, le président des États-Unis Barack Obama a enflammé la critique après qu’un Livre blanc de la Maison Blanche ait encouragé la traduction automatique[11],[12].
Décennie 2010
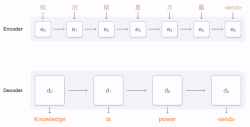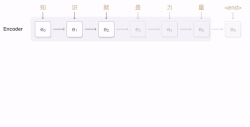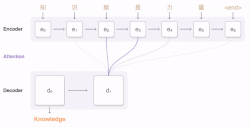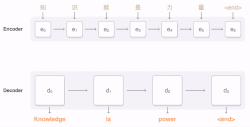
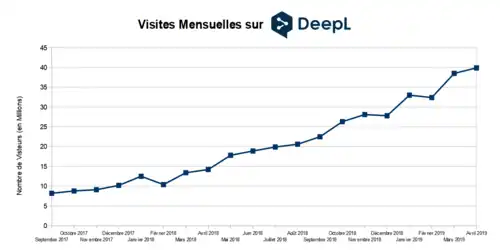
Dans la décennie 2021 les méthodes traduction automatique neuronale (NMT) remplacent le statistical machine translation. L'expression neural machine translation (qui donne traduction automatique neuronale) est forgée par Bahdanau et al[13] et par Sutskever et al[14] qui ont aussi publié la première recherche sur ce sujet en 2014. Les réseaux neuronaux ne nécéssitaient qu'une fraction de la mémoire nécéssaire aux modèles statistiques et des phrases entières peuvent être modélisées de manière intégrée. Le premier NMT a large échelle a été lancé par Baidu en 2015, suivi par Google Neural Machine Translation (GNMT) en 2016. Cela fut suivi par d'autres services de traduction comme DeepL Translator et l'adoption de la technologie NMT dans des services de traduction antérieurs comme Microsoft translator.
Les réseaux neuronaux utilisent une seule network architecture neuronale de bout-en-bout connue comme sequence to sequence (seq2seq) qui utilise deux recurrent neural networks (RNN). Un RNN encodeur et un RNN décodeur. Le RNN encodeur utilise des vecteurs encodant sur la phrase source et le RNN décodeur génère la phrase cible sur la base du vecteur précédant obtenu[citation nécessaire] D'autres avancées dans la couche d'attention, les techniques de transformation et de back propagation ont rendu les NMTs flexibles et adaptés à la plupart des technologies de traduction automatisées, de synthèse et de chatbot[15].
Décennie 2020
Modèle:Update section
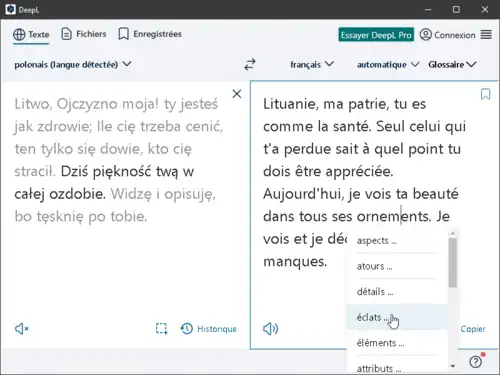
Depuis 2020, Google a rendu la traduction automatique de discours ou de conversations orales accessible depuis des téléphones portables[16].
En 2025, des sources révèlent qu'une large part des contenus web est produite par traduction automatique via l'intelligence artificielle, notamment dans les langues minoritaires[17].
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « History of machine translation » (voir la liste des auteurs).
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 https://journals.openedition.org/histoire-cnrs/3461
- ↑ La première version de ce memorandum a été publié à Carlsbad (Nouveau Mexique) en juillet 1949. Il a été reproduit dans Machine Translation of Languages, Cambridge, Massachusetts, MIT Press, , 15–23 p. (ISBN 0-8371-8434-7, lire en ligne), « Translation »
- ↑ https://courier.unesco.org/fr/articles/le-traducteur-une-espece-en-voie-de-disparition
- ↑ [PDF] (en) John Hutchins, « "The whisky was invisible", or Persistent myths of MT »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?), MT News International, , p. 17-18.
- 1 2 3 4 5 6 7 8 9 10 11 https://www.revuegeneraledudroit.eu/blog/decisions/cjue-18-avril-2013-commission-europeenne-contre-systran-sa-et-systran-luxembourg-aff-nc-103-11-p/
- ↑ « PROCUREMENT PROCESS » [archive du ], sur Canadian International Trade Tribunal, (consulté le )
- ↑ Makoto Nagao, Proc. of the International NATO Symposium on Artificial and Human Intelligence, North-Holland, , 173–180 p. (ISBN 978-0-444-86545-8), « A framework of a mechanical translation between Japanese and English by analogy principle »
- ↑ « the Association for Computational Linguistics – 2003 ACL Lifetime Achievement Award » [archive du ], Association for Computational Linguistics (consulté le )
- ↑ John Weisgerber, Jin Yang et Pete Fisher, Envisioning Machine Translation in the Information Future, vol. 1934, coll. « Lecture Notes in Computer Science », , 196–201 p. (ISBN 978-3-540-41117-8, DOI 10.1007/3-540-39965-8_21, S2CID 36571004), « Pacific Rim Portable Translator »
- ↑ « TC-Star » (consulté le )
- ↑ White House Challenges Translation Industry to Innovate
- ↑ Letter from ATA to President Obama
- ↑ Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk et Yoshua Bengio, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Stroudsburg, PA, USA, Association for Computational Linguistics, , 1724–1734 p. (DOI 10.3115/v1/d14-1179, arXiv 1406.1078, S2CID 5590763), « Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation »
- ↑ Yuuki Tachioka, Shinji Watanabe, Jonathan Le Roux et John R Hershey, 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), IEEE, , 572–576 p. (ISBN 978-1-4799-7088-9, DOI 10.1109/globalsip.2014.7032182, S2CID 767028), « Sequence discriminative training for low-rank deep neural networks »
- ↑ (en) « What is Neural Machine Translation & How does it work? », sur TranslateFX (consulté le )
- ↑ « Traduction automatique : l'IA est en train de faire tomber la barrière de la langue... », sur Science-et-vie.com, (consulté le ).
- ↑ « Une grande partie de ce qui est écrit sur Internet a été traduit par une IA, selon une étude », sur France Inter, (consulté le ).
Liens externes
 Portail de l’écriture
Portail de l’écriture _artificial_intelligence_icon.png) Portail de l’intelligence artificielle
Portail de l’intelligence artificielle